Comment fonctionne l’indexation d’une page ?




Avant toute chose, il faut comprendre le fonctionnement des moteurs de recherche. En effet, avant de rendre votre page visible sur la SERP (Search Engine Result Page), les robots de Google (ou Google bot) vont devoir analyser votre site. Pour ce faire, ils vont procéder ainsi :
- L’exploration : lors de cette étape, les robots de Google vont explorer votre page afin de prendre connaissance de son contenu.
- L’indexation : suite à l’exploration de la page de votre site web, Google va la stocker dans son index. Vous pouvez voir cela comme une immense bibliothèque où les livres sont rangés (indexés) par catégorie, thématique et pertinence.
- Le positionnement : au vu du grand nombre de contenus présents sur le web (en 2016, Google a indexé 130 000 milliards de pages de sites internet 🤯), Google définit un positionnement des pages en fonction de leur pertinence, tel une bibliothécaire qui vous proposerait le livre le plus adapté à votre besoin.
- L’affichage : après avoir pris connaissance du contenu, l’avoir enregistré dans sa base de données et de lui avoir attribué une position, Google affiche enfin votre page dans la SERP.
Nous nous concentrerons donc dans cet article sur l’étape de l’indexation. Vous l’aurez compris, cette étape est primordiale. Sans elle, votre page ou votre site ne pourra pas faire partie des résultats de recherche. De ce fait, aucun utilisateur ne pourra vous trouver et accéder à votre site.
Mais le processus d’indexation de la page de votre site web ne sera pas la même si vous êtes Amazon ou un site fraîchement créé.
Dans le cas d’un site déjà présent sur Google depuis 3 ans, la majeure partie de ses pages sont indexées et les robots de Google reviennent régulièrement inspecter le contenu de son site web. Le temps passé par les robots de Google à crawler votre site et sa fréquence de crawl sont définis par le crawl budget. Il variera en fonction du nombre de pages de votre site, de son nombre de visites quotidiennes, de son ancienneté, etc.
De ce fait, Amazon disposera d’un crawl budget plus élevé qu’un site d’une dizaine de pages, comptabilisant 100 visiteurs par jour et existant depuis moins de 2 ans. Durant cette étape de crawl, les robots google pourront donc prendre connaissance d’une nouvelle page fraichement publiée et l’indexer.
Dans le cas où votre site est fraîchement publié sur internet, vous devez indiquer à Google que vous existez. Pour ce faire, il faut réaliser l’indexation des pages de votre site web.
Comment indexer son site sur Google ?
Maintenant que vous avez compris le fonctionnement des moteurs de recherche et de l’indexation, nous pouvons rentrer dans le vif du sujet : comment procéder pour que Google indexe mon site ou une page de mon site ? Il existe différentes techniques permettant d’indexer une page sur Google, voici les principales :
L’indexation avec Google Search Console
L’utilisation de la Google Search Console est la technique la plus efficace pour demander l’indexation de son site web ou d’une page. Cet outil, développé par Google est complètement gratuit et simple d’utilisation. Il vous permettra de soumettre l’intégralité de votre site ou une seule page aux robots de Google.
Pour ce faire, vous devez tout d’abord ajouter “une propriété de site Web” à la Search Console. Pour effectuer cette manœuvre, vous serez guidé pas à pas grâce aux informations fournies. Vous pouvez également consulter la documentation de Google à ce sujet.
Une fois l’outil paramétré, vous pourrez effectuer une demande d’indexation. Pour réaliser l’indexation d’une page via le Google Search Console :
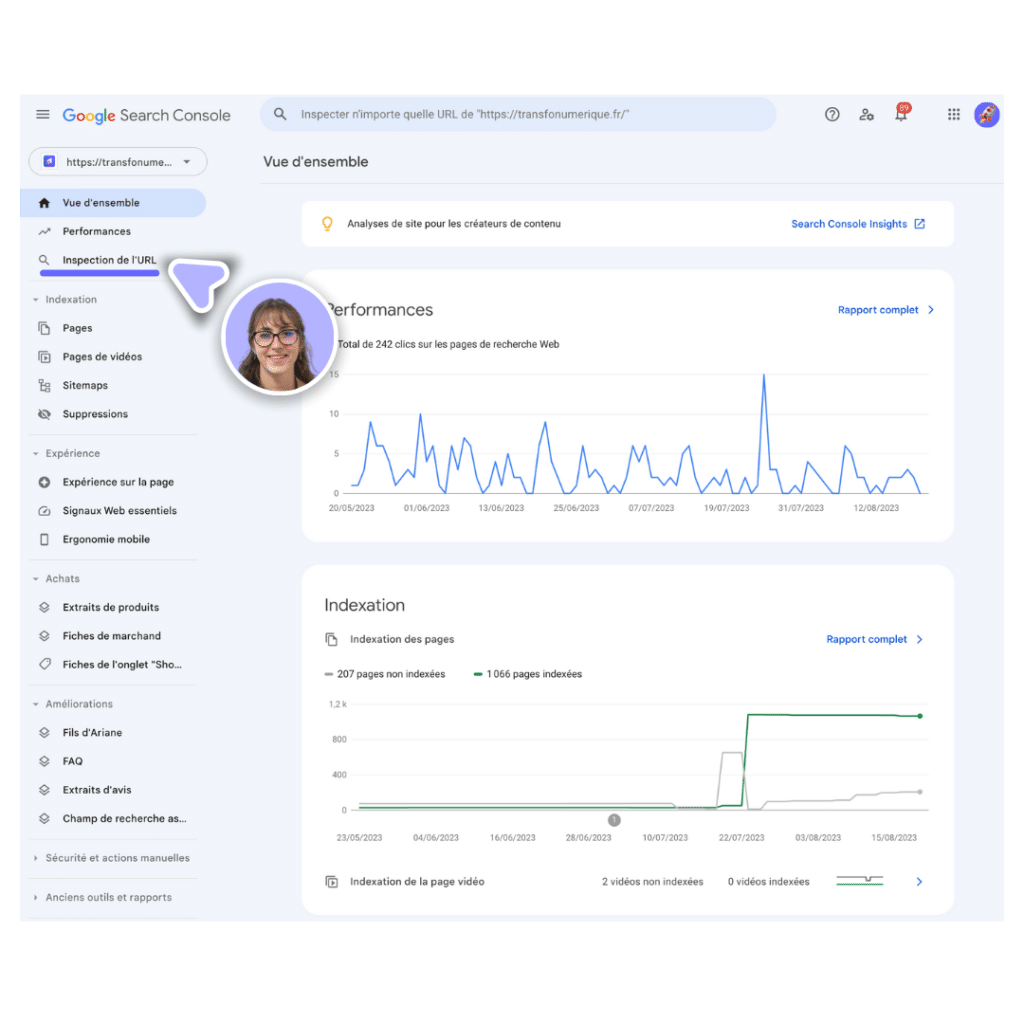
- Rendez-vous dans l’onglet “inspection de l’URL”
- Renseignez l’URL de la page que vous souhaitez indexer sur Google
- Vérifiez l’état d’indexation : “Cette URL est sur Google” (page déjà indexée) ou “Cette URL n’a pas été indexée par Google” (page jamais indexée)
- Cliquez sur “Demander une indexation »
Grâce à la Google Search Console, vous pourrez effectuer le suivi de l’état d’indexation de chacune des pages de votre site. Vous pourrez analyser les performances de votre site, identifier les problèmes bloquant l’indexation des pages et bien évidemment effectuer des demandes d’indexation.
L’indexation avec le fichier robots.txt
Le fichier robots.txt est un fichier à implémenter à la source du code de votre site. Ce fichier permet d’indiquer aux robots de Google quelle page de votre site, il doit ou non indexer.
À l’aide de quatre balises “Allow” (autoriser), “Disallow” (refuser), “noindex” (pas d’index) et “crawl delay” (délai d’exécution) vous indiquerez aux robots quels URLs ils sont autorisés ou non à explorer, à indexer et le temps d’attente entre chaque requête.
Si votre fichier robots.txt est déjà créé, nous vous invitons à vérifier que les URLs que vous souhaitez indexer ne comprennent pas de balises “Disallow” ou “Noindex”. Auquel cas, les robots seront bloqués dans leur tâche. Dans le fichier robots.txt est également présent le Sitemap.xml. Le sitemap.xml est comme un GPS pour les robots de Google, leur facilitant l’exploration de votre site. Il est donc important d’en avoir un.

L’indexation avec le fichier sitemap.xml
Comme son nom l’indique, le sitemap est un plan de votre site destiné aux robots de Google. Il vous permet d’indiquer aux robots différentes informations telles que : la date de publication (ou de dernière modification) de votre page, la fréquence à laquelle elle doit être crawlée et le niveau de priorité de la page en fonction de chaque URLs.
L’avantage avec le sitemap.xml, c’est que vous pouvez transmettre directement son URL à la Google Search Console pour indexer toutes les URLs. Pour cela, rendez-vous dans l’onglet “Sitemap” du menu de navigation de la Search Console.

L’indexation grâce au maillage interne
Le maillage interne désigne l’ensemble des liens internes présents sur votre site. Soit un lien sur la page A renvoyant à la page B de votre site, et ainsi de suite.
Pour indexer les pages de votre site, les robots Google suivent l’ensemble des liens présents sur vos pages. Il est donc important de faire des liens entre ces dernières, non seulement pour permettre aux robots d’explorer toutes vos pages, mais également pour offrir une meilleure expérience à vos utilisateurs.
L’indexation avec les backlinks
Pour indexer vos pages rapidement, nous vous conseillons de mettre en place une stratégie de netlinking. Cela vous permettra d’obtenir des liens d’autre site : des backlinks. Ainsi, lorsque les robots crawleront le site contenant un backlink, ils exploreront également les pages de votre site.
L’indexation grâce au plan de site
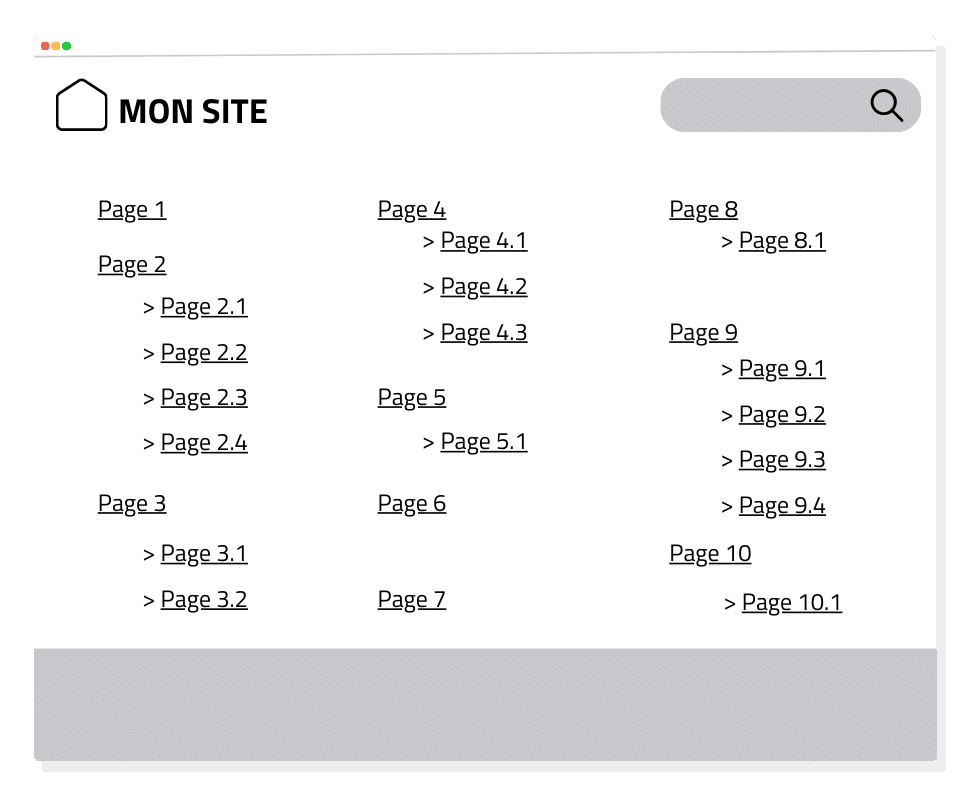
À la différence du sitemap, qui est visible uniquement par les robots de Google, le plan de site est quant à lui présent sur votre site. C’est une page de votre site, généralement présente dans le footer, qui recense toutes ses pages. Il est donc naturellement utilisable par les robots et par les utilisateurs du site.
Il est conseillé de disposer d’un plan de site lorsque votre site est très fourni. Il sera alors complètement inutile sur un site ne disposant que de 5 pages. Cette page de plan de site permet ainsi de transmettre aux robots de Google l’ensemble des pages présentes sur votre site, ce qui facilite grandement le travail des robots Google.
⚠️ Attention, l’utilisation d’un plan de site ne doit pas exclure l’utilisation d’un sitemap.xml.
Comme nous venons de le voir, il existe de nombreuses possibilités pour réussir à indexer son site sur Google. La plupart des méthodes sont complémentaires. L’utilisation de Google Search Console reste primordiale tant pour l’indexation, que pour le suivi de cette dernière, mais principalement pour vous permettre d’identifier les problèmes bloquant l’indexation de vos pages.
Quels problèmes peuvent bloquer l’indexation de votre site sur Google ?
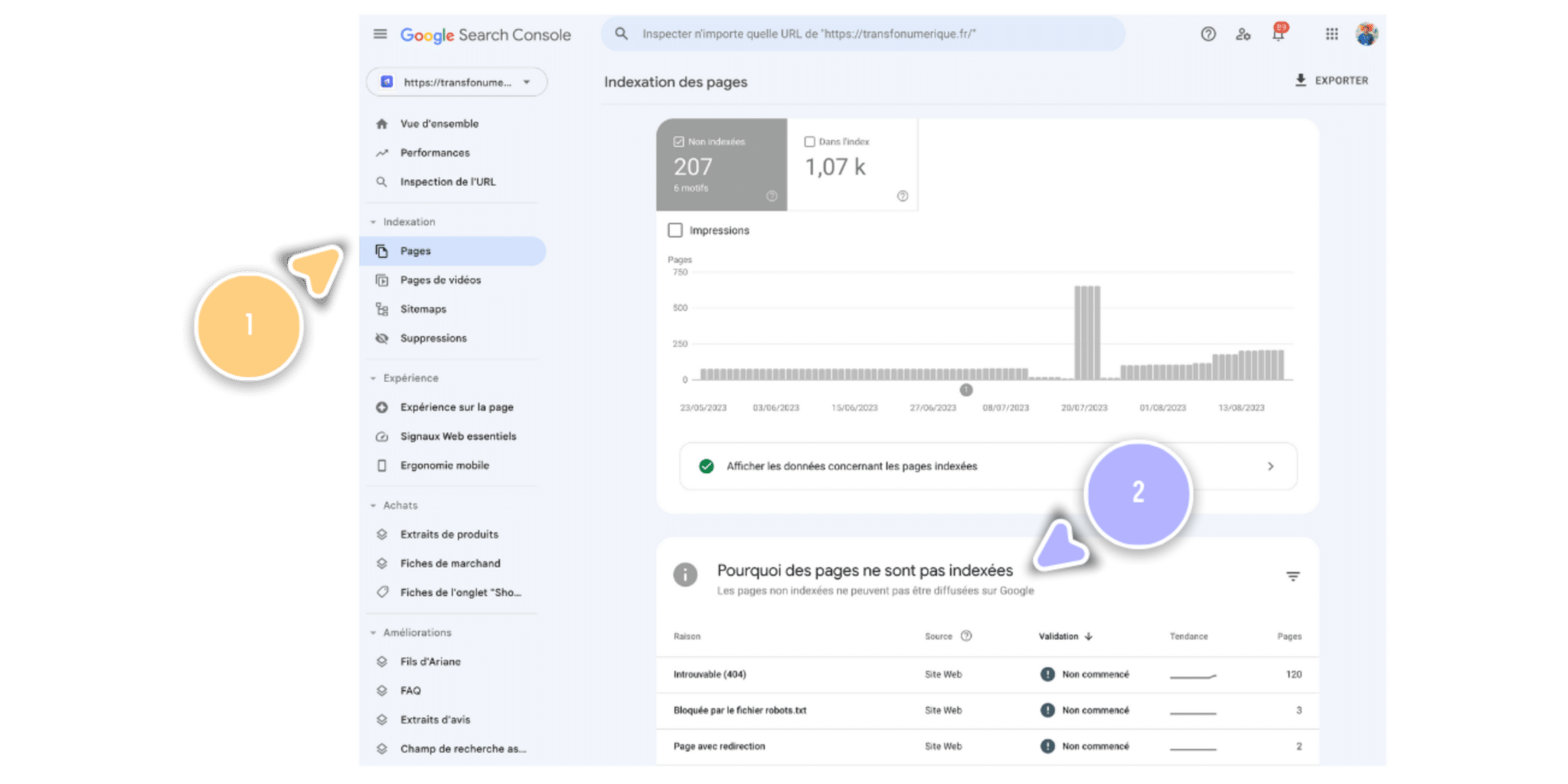
Suite à l’indexation de votre site, il est très important de vérifier régulièrement l’état d’avancement de l’indexation de vos pages. Lors de cette vérification, vous pourrez rencontrer des pages qui, même après une soumission à la Search Console, ne sont pas indexées. Plusieurs causes peuvent être à l’origine de problèmes bloquant l’indexation.
Voici une liste (non exhaustive) des problèmes que vous pouvez rencontrer lors de cette étape :
- Le contenu de votre page
- Le temps de chargement de votre site
- Le fichier .htacess
- Les pages 404
- Les balises canoniques
- Les pages en JavaScript
- Le fichier robots.txt
1. Le contenu de votre page bloque son indexation
Plus votre contenu sera qualitatif, plus il remontera dans les résultats de la SERP. Toutefois, un contenu de faible qualité ou dupliqué sera bloqué lors de l’indexation. Ainsi, si votre contenu est dupliqué sur tout ou partie de la page, Google ne procédera pas à l’indexation de la page, car son contenu existe déjà dans son index et n’apporte rien de nouveau aux utilisateurs.
Dans le pire des cas, si votre site contient trop de contenu dupliqué (interne et externe), vous subirez des pénalités par Google. En effet, depuis 2011, Google a mis à jour son algorithme “Panda” pour favoriser les contenus de qualité et pénaliser le contenu dupliqué.
Avant de soumettre une page à l’indexation, nous vous conseillons donc de vérifier que son contenu soit à 100 % unique avec des outils tels que Sceaming Frog, pour vérifier les contenus dupliqués en interne, et duplichecker.com pour vérifier les contenus dupliqués externes à votre site.
2. Le temps de chargement de votre site
Comme nous l’avons vu ci-dessus, votre site dispose d’un temps de crawl défini. Il est donc important de bénéficier d’un temps de chargement des pages rapide pour vos utilisateurs, mais également pour les robots de crawl de Google. En effet, plus le temps de chargement sera élevé, moins les robots de crawl pourront explorer de pages.
Pour limiter les problèmes d’indexation de vos pages par Google, nous vous conseillons d’optimiser les performances de votre site. Pour ce faire, vous pouvez utiliser l’outil Google Page Speed ou l’outil GTmetrix. Ces outils vous indiqueront quelles sont les opportunités d’optimisation de votre site permettant d’optimiser le temps de chargement de votre site.
3. Le fichier .htacess
Le fichier .htacess est un fichier de configuration présent à la racine de votre site web. Il permet de gérer des fonctionnalités du serveur telles que les redirections, protéger un répertoire de lien ou bien contrôler l’accès à votre site.
Si votre site dispose d’un fichier .htacess, vous devez vérifier si ce dernier ne bloque pas l’accès aux données de votre site aux robots de Google. Si c’est le cas, ils ne pourront pas l’explorer et, de ce fait, l’indexer sur Google. Si vous rencontrez cette problématique, vous devrez simplement modifier le fichier .htacess. Pour cela, nous vous conseillons de réaliser en amont une sauvegarde de votre site pour ne perdre aucune donnée.
4. Les pages 404
Les pages 404 sont des pages qui n’existent pas, soit, car elles viennent d’être supprimées et ne possèdent pas de lien de redirection, soit parce que leur URL a été mal saisie. Ce type d’erreur peut bloquer l’indexation d’une page, mais pas celle de l’intégralité du site.
Vous pouvez également rencontrer une erreur d’indexation Google. Ce type de problème peut survenir par exemple sur un site multilingue qui disposerait d’une page existante en français, mais pas en anglais. Pour remédier à ce problème, nous vous conseillons de mettre en place une redirection 301 pour limiter les erreurs soft 404.
5. Les balises canoniques
Dans le cas d’un site e-commerce notamment, votre site peut disposer de balises canoniques. Les balises canoniques sont présentes dans la section <head> de votre site. Elles permettent d’indiquer qu’une page dépend d’une autre.
Exemple : la page “chaussure” dispose d’une sélection de filtres permettant de trier les articles de la page. Lorsque vous activez l’un de ces filtres, l’URL est modifiée, cependant le contenu (trié) est le même. De ce fait, vous mettez en place des balises canoniques pour éviter d’avoir du contenu dupliqué.
Google n’indexera pas les pages canoniques, mais uniquement la page originale.
6. Les pages en JavaScript
Il est important de savoir que les robots de Google ne sont pas en capacité de lire le contenu JavaScript d’une page web. De ce fait, si le contenu de votre page est intégralement en JS, il y a de grandes chances que votre contenu ne soit pas indexé. En effet, les robots de Google n’indexeront pas une page qui est vide, car cela n’a aucun intérêt ni pour l’utilisateur, ni pour Google.
Pour vérifier si votre page contient du JS, vous pouvez utiliser l’extension “Développeur” de Google Chrome. Cliquez sur “Disable JavaScript”, dans l’onglet “Disable”. Si l’ensemble du contenu de la page disparaît, c’est que votre contenu est intégralement codé en JS. Il faudra donc le modifier.
7. Le fichier robots.txt
Comme vu ci-dessus, le fichier robots.txt vous permet d’indexer vos pages, mais aussi d’exclure certaines pages du processus d’indexation de Google. En effet, si vous indiquez qu’un certain répertoire, catégorie de pages ou partie qu’un site web, sont interdits d’accès aux robots d’indexation de Google, ils ne pourront pas les indexer. Ainsi, si vous rencontrez ce problème lors de l’indexation, il vous suffira de modifier le fichier robots.txt pour procéder à l’indexation de la page, d’une partie de site ou d’une catégorie de page.
Pour conclure, l’indexation est une étape primordiale permettant à votre site de faire partie de la base de données de Google. Pour y être accepté, vous devez proposer du contenu intéressant et original et votre site doit être bien conçu. Nous vous conseillons fortement d’utiliser des outils tels que le fichier sitemap.xml et autres pour faciliter le travail aux robots d’indexation de Google. Pour procéder à l’indexation de votre site web, l’outil Google Search Console sera votre meilleur ami 🤓 Il vous permettra de soumettre des pages à l’index de Google, d’identifier les problèmes d’indexation et tant d’autres applications.
Si vous rencontrez des difficultés dans la réalisation de l’indexation de votre site web, vous pouvez nous contacter dès à présent.